Концепция поиска элементов на странице
Существует две основные концепции поиска элементов на странице:
- Регулярные выражения
- XPath
Регулярные выражения
Более распространённым вариантом принято считать регулярные выражения. У них есть большой минус, часто на нужной странице что то меняется например вёрстка, и регулярное выражение перестаёт работать. В таком случае придётся вспоминать что там к чему. Хотя не факт что это у Вас получится.
Вы вероятно и не вспомните как именно устроена регулярка которую вы писали пару дней назад, т.к. визуальное восприятие у регулярных выражений очень плохое. К тому же некоторые элементы могут уже отсутствовать на странице. Именно поэтому Вам скорее всего придётся составлять регулярку с нуля.
XPath
Преимуществом XPath перед регулярными выражениями, является то, что он гораздо более прост для визуального восприятия. При этом он достаточно гибок и универсален. Там где пришлось бы городить какую то сложную регулярку, XPath справится просто и лаконично.
Если в коде страницы что то изменилось, достаточно будет использовать старый путь XPath по частям. Первая часть сработала -> ищем следующий элемент и так до тех пор пока не найдём ошибку, которая возникла, например, в связи со сменой имени класса у дива.
Работа с XPath: Практика
Я придерживаюсь принципа, не стоит создавать с нуля то что уже есть и достаточно хорошо описано. Поэтому я оставлю вам несколько уроков по которым учился работать с XPath сам.
Дополнительно оставляю Вам такую Шпаргалку для работы с XPath.
Если вы используете любой хромо-подобный браузер, Вам скорее всего пригодится вот этот плагин XPath Helper. Для FF, возможно, добавлю чуть позже.
Работа с XPath: Практика
Настало время перейти к практике. Имейте в виду что некоторые примеры со временем могут устаревать. Но это, разумеется, относится к самим сайтам на которых мы тренируемся, а не к XPath в целом.
Оси XPath
Структура поиска элементов похожа на географический адрес или на древо элементов. Существуют разнообразные направления для поиска элементов, их называют оси XPath.
Оси указывают в каком направлении двигаться. Иногда бывают разные ситуации, в которых искомый элемент не обладает какими то уникальными свойствами, но при этом мы знаем что он вложен в какой то другой элемент или находится по соседству с другим уникальным элементом. Используя оси мы можем найти элемент так сказать обходными путями.
descendant:: - Выбирает всех потомков текущего узла. Можно заменить на «.//»
descendant-or-self:: - Выбирает всех потомков текущего узла и сам текущий узел.
ancestor:: - Выбирает всех предков текущего узла.
ancestor-or-self:: - Выбирает всех предков текущего узла и сам текущий узел.
parent:: - Выбирает родителя текущего узла. Можно заменить на «..»
self:: - Выбирает текущий узел. Можно заменить на «.»
following:: - Выбирает все элементы в документе после закрывающего тега текущего узла.
following-sibling:: - Выбирает все элементы одного уровня после текущего узла.
preceding:: - Выбирает все узлы, которые появляются перед текущим узлом, за исключением предков, узлов атрибутов и пространства имен.
preceding-sibling:: - Выбирает все элементы одного уровня до текущего узла.
namespace:: - Выбирает все узлы пространства имен текущего узла.
attribute:: - Выбирает все атрибуты текущего узла. Можно заменить на «@».
Простейший пример использования осей
Contains
Бывает у элемента нет никакого уникального класса, либо он генерируется случайным образом. В таком случае удобнее всего будет поискать элемент используя свойство contains, что означает содержит.
Например на сайте Авито, чтобы найти и кликнуть по кнопке навигации следующая страница, достаточно воспользоваться таким XPath

Starts-with
Иногда бывает удобно составлять выражения XPath с оператором starts-with. Это выражение интуитивно понятно, так что сразу перейдём к примеру.
div в котором находится тег a, у которого атрибут href начинается с tel:
Концепция пути XPath
Пример посложнее. На сайте Авито мы хотим получить все значения элементов карточек товаров. При изучении сайта мы приходим к выводу, что некоторые названия нужных нам элементов также содержатся в блоке с рекламой, которая никак не относится к нашему условию поиска, мы хотим взять только то что ищем, без какой либо рекламы.
В этом случае в нашем XPath мы указываем всю последовательность уникальных элементов, вплоть до тех что мы ищем.
Другими словами мы последовательно формируем тропинку из уникальных элементов и / или их свойств, в которых содержаться искомые элементы. В конечном итоге мы приходим к нашей поляне, которую мы изначально искали, и нам совершенно не важно что где то ещё на странице есть элементы с похожими свойствами или атрибутами - мы ищем только в пределах поляны к которой мы пришли.
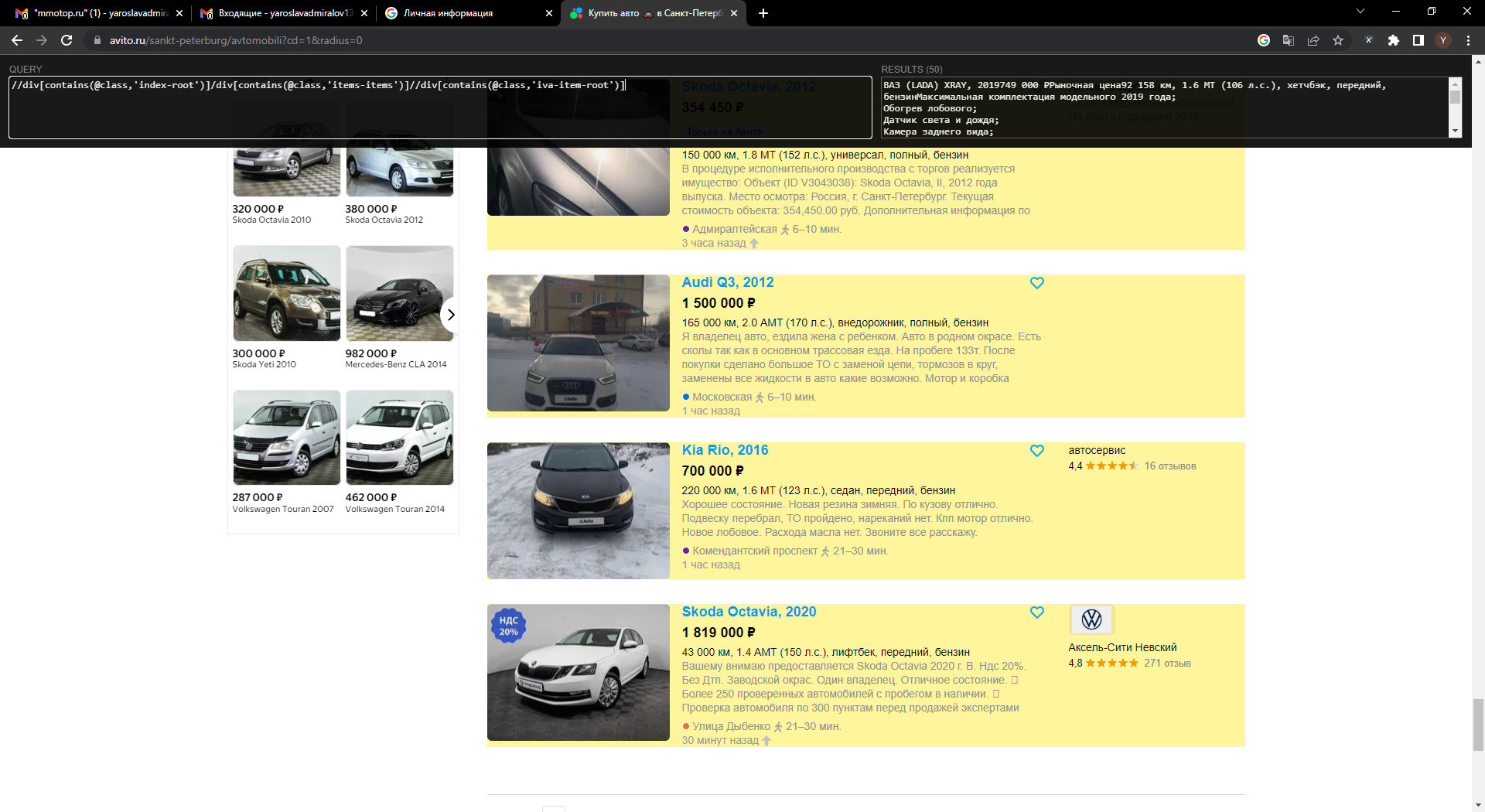
Поиск по атрибуту (class, a, input и т.д.)
Используя этот метод мы привязываемся к свойству элемента атрибута.
Предположим на странице есть картинка i по которой мы хотим кликнуть. У этой картинки есть уникальный class который называется icon-phone-white
Условие or
Тут ничего необычного. Всеми известное условие или.
Найди div с классом hello или текстом test
Логический оператор and
Когда по одному признаку находятся сразу несколько элементов, мы можем задействовать механизм который чем то напоминает SQL. Мы в пути прописываем конструкцию and(которая переводится как и).
Таким образом логика запроса превращается в найди мне элемент с таким то классом + чтобы в нём дополнительно содержался текст. Это бывает полезно чтобы быстро отфильтровать похожие элементы, получив в итоге уникальный искомый элемент.
Как на зло не смог за минут 10 найти конкретный пример, поэтому показываю на примере VK. Думаю смысл понятен, например при поиске span с классом FlatButton__content находятся несколько элементов, но мы в XPath дополнительно уточняем что элемент должен ещё содержать Sign in, таким образом мы получаем 1 уникальный элемент на странице.
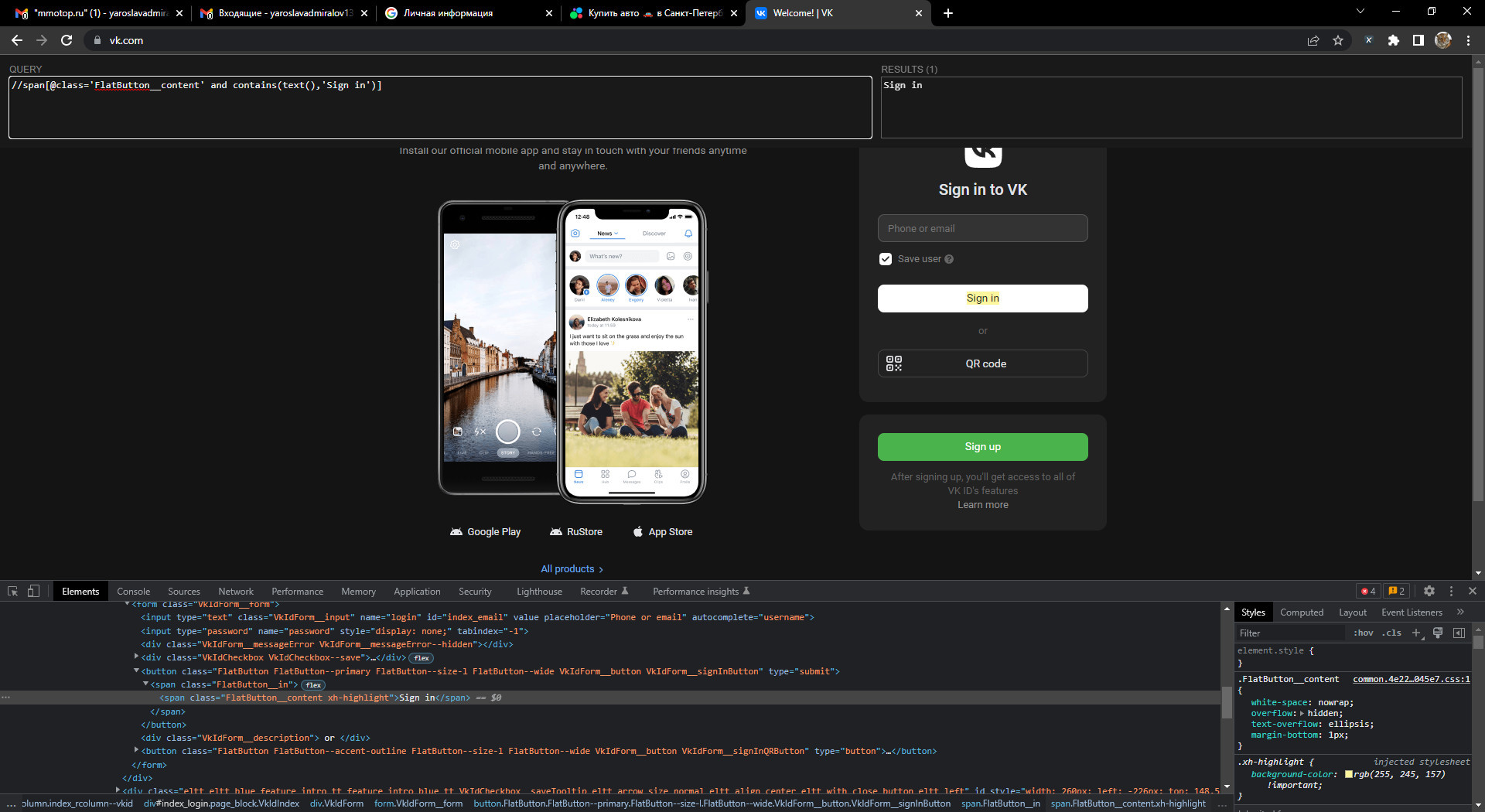
Ещё 1 пример комбинирования. Тут вроде бы всё интуитивно понятно.
В выражении XPath может быть сразу несколько условий and
По мере поступления новой инфы буду периодически обновлять этот пост.
Отправить комментарий